Set up the WITSML extractor
The Cognite WITSML extractor is distributed as a Docker container. The steps described in this section use the simple deployment setup.
Before you start
- Check the server requirements for the extractor.
- Make sure the extractor has the following access capabilities in a Cognite Data Fusion (CDF) project:
timeseries:read,timeseries:write, andtimeseries:listsequences:read,sequences:write, andsequences:listraw:read,raw:write, andraw:listextractionpipelines:write
You can use OpenID Connect and your existing identity provider (IdP) framework to manage access to CDF data securely. Read more.
Set up data sets to store the WITSML configuration data (
RAW_DB_FOR_CONFIG) and the WITSLM extracted data (RAW_DB_FOR_DATA).Create a configuration file according to the configuration settings. The file must be in YAML format.
Run as a Docker container
Make sure you're signed into the Cognite Docker Registry.
Enter this
docker runstatement:docker run -v $(pwd)/config.yaml:/config.yaml \
-it eu.gcr.io/cognite-registry/witsml-connector:<version>Make sure the extractor runs by verifying that
Next wakeup is dueis displayed:
---
2022-10-14 10:51:48,247 - INFO - root - Starting
2022-10-14 10:51:48,248 - INFO - apscheduler.scheduler - Adding job tentatively -- it will be properly scheduled when the scheduler starts
2022-10-14 10:51:48,248 - INFO - apscheduler.scheduler - Adding job tentatively -- it will be properly scheduled when the scheduler starts
2022-10-14 10:51:48,249 - INFO - apscheduler.scheduler - Adding job tentatively -- it will be properly scheduled when the scheduler starts
2022-10-14 10:51:48,250 - INFO - apscheduler.scheduler - Added job "well.all" to job store "default"
2022-10-14 10:51:48,250 - INFO - apscheduler.scheduler - Added job "wellbore.all" to job store "default"
2022-10-14 10:51:48,250 - INFO - apscheduler.scheduler - Added job "find_and_post_scheduled_queries" to job store "default"
2022-10-14 10:51:48,250 - INFO - apscheduler.scheduler - Scheduler started
2022-10-14 10:51:48,251 - DEBUG - apscheduler.scheduler - Looking for jobs to run
2022-10-14 10:51:48,251 - DEBUG - apscheduler.scheduler - Next wakeup is due at 2022-10-14 10:52:00+00:00 (in 11.748631 seconds)
Deploy the extractor
You define how the extractor handles low or high data volumes with the mode configuration parameter:
Simple deployment
Set mode to SIMPLE for low data volume integrations between the WITSML server and CDF. With this setting, the extractor only handles changed objects and can't scale. This is the out-of-the-box deployment available in the Docker image.
To ingest all historical data combined with growing objects, use the advanced deployment methods for scalable integrations.
Use this mode for projects with:
- 1–5 active wellbores.
- 1–5 object types to ingest.
- 1–5 growing objects.

Advanced deployment
Use this deployment for high data volumes and change rates, typically complex extractions that needs further scalability.
The advanced deployment needs a specific configuration to fit your use case. If your scenario fits one of the options below, contact your Cognite representative.
Scalable extractions using SOAP
Use this mode for projects with:
- More than 10 active wellbores.
- More than 15 object types to ingest.
- More than 30 growing objects.
- Extraction workers can be scaled.
- Extraction of historical records.

Scalable extractions using SOAP and ETP
You can use the extractor with the ETP protocol in the Scalable and ETP deployment mode. Use this mode for projects with:
- More than 10 active wellbores.
- More than 15 object types to ingest.
- More than 30 growing objects.
- Extraction workers can be scaled.
- Extraction of historical records.
- Extraction of live data using ETP protocol.

To extract data using ETP, you must connect two extra modules to the to WITSML server:
- ETP receiver creates the web-socket session and listens for changes. Single worker that will handle all ETP subscriptions.
- ETP ingestor transforms WITSML data extracted from ETP to the respective CDF resources (
sequencesortime series). This is a scalable worker that handles ingestions of multiple live data.
These modules require a special configuration. If you have a use case with ETP real-time logging, contact your Cognite representative.

Monitor extractions
Set up Extraction pipelines to monitor the data extractions. The first time you run the extractor, it creates the extraction pipeline entries and then logs succeeding runs with a success or failed status.
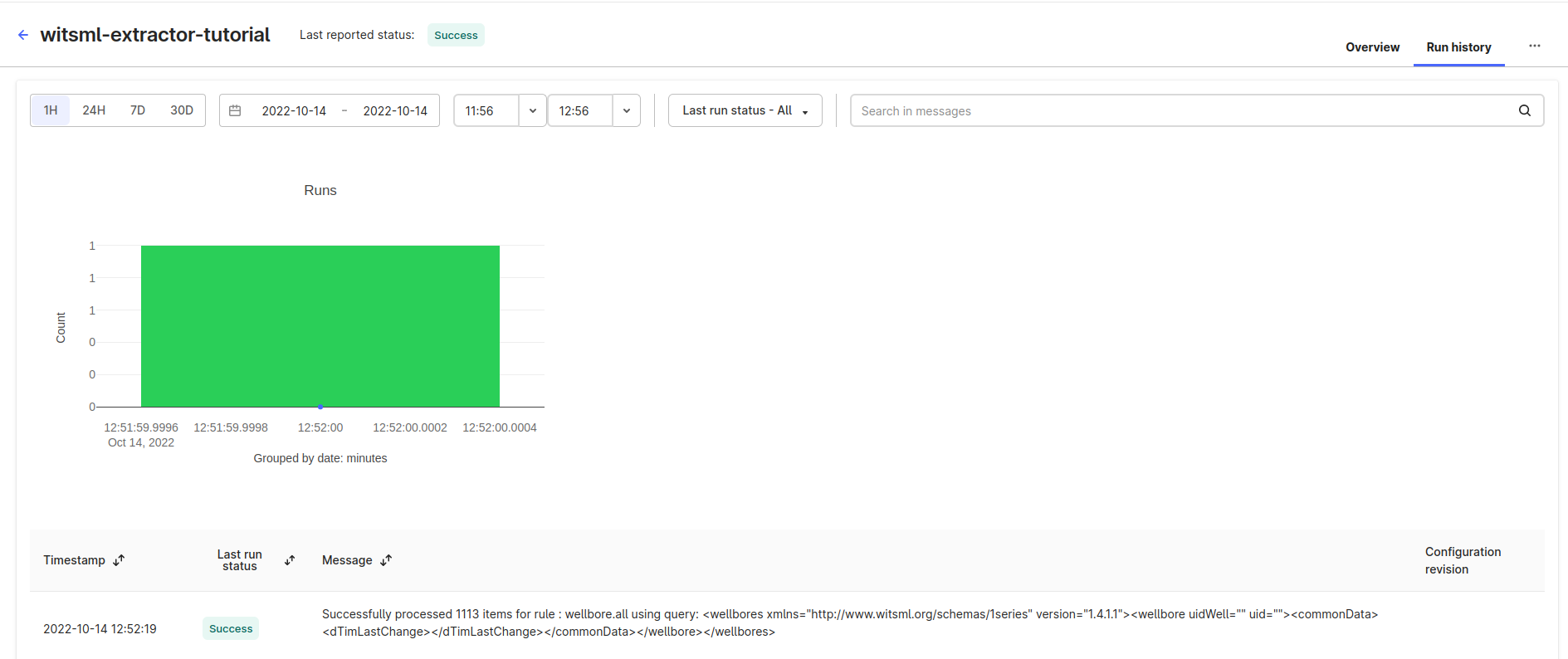
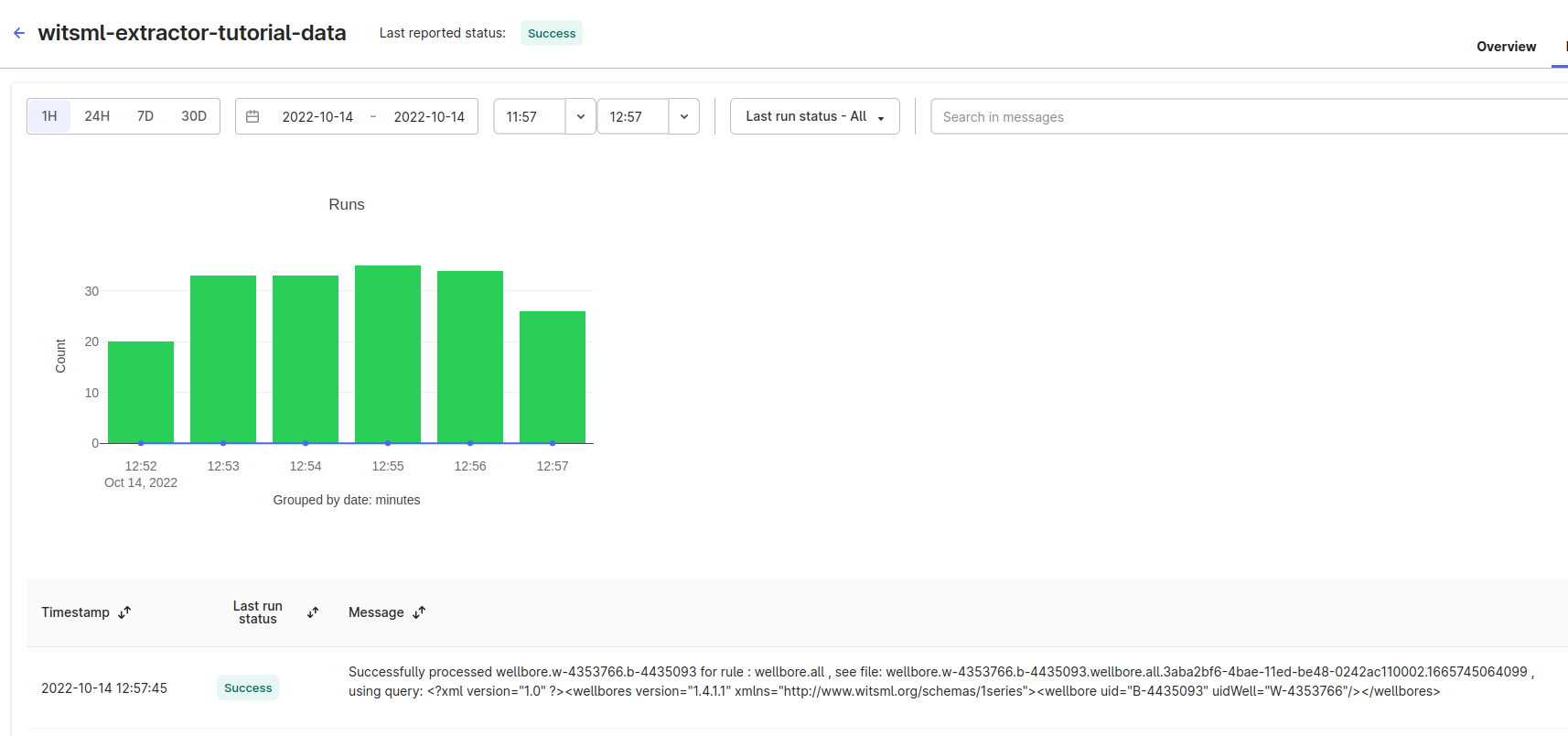
You'll see the extraction runs as two different sections on the Run history tab on the Extraction pipeline page:
The extractor stores runs related to the query scheduler:
The extractor stores runs related to the data ingestion to CDF:
All issues related to the extractor execution are logged in the extraction pipelines, including query issues in the WITSML server.
Scheduled SOAP queries
Scheduled queries come in two variants:
- Scheduled list query: Looks for changes.
- Scheduled object query: Downloads changes.
Capturing the changes is separated from the actual data download to support scaling.
For SOAP queries, note these observations:
- The WITSML server can have a maximum number of requests per second, depending on your WITSML server setup. You must evaluate this with your WITSML vendor to avoid overloading the server.
- The XML returned from the server doesn't always comply with the WITSML standard. When this happens, the extraction fails since the data mapping performed by the extractor is based on the WITSML standard schema.
- A request can fail if there's bad data on some returned data objects.
- The amount of data for some objects can be 100+MB.
- Not all data is returned if the size of the data object is above a threshold. New requests must be sent to the server to retrieve missing data.
Explore the extracted data
You can explore the extracted data by navigating in CDF RAW or the respective CDF resource types (for WITSML growing objects).
Data stored in CDF resource types
WITSML logs are stored in CDF as time series (for time-based logs) and sequences (depth-based logs). You can navigate and check the extracted data in CDF.
Data stored in CDF RAW
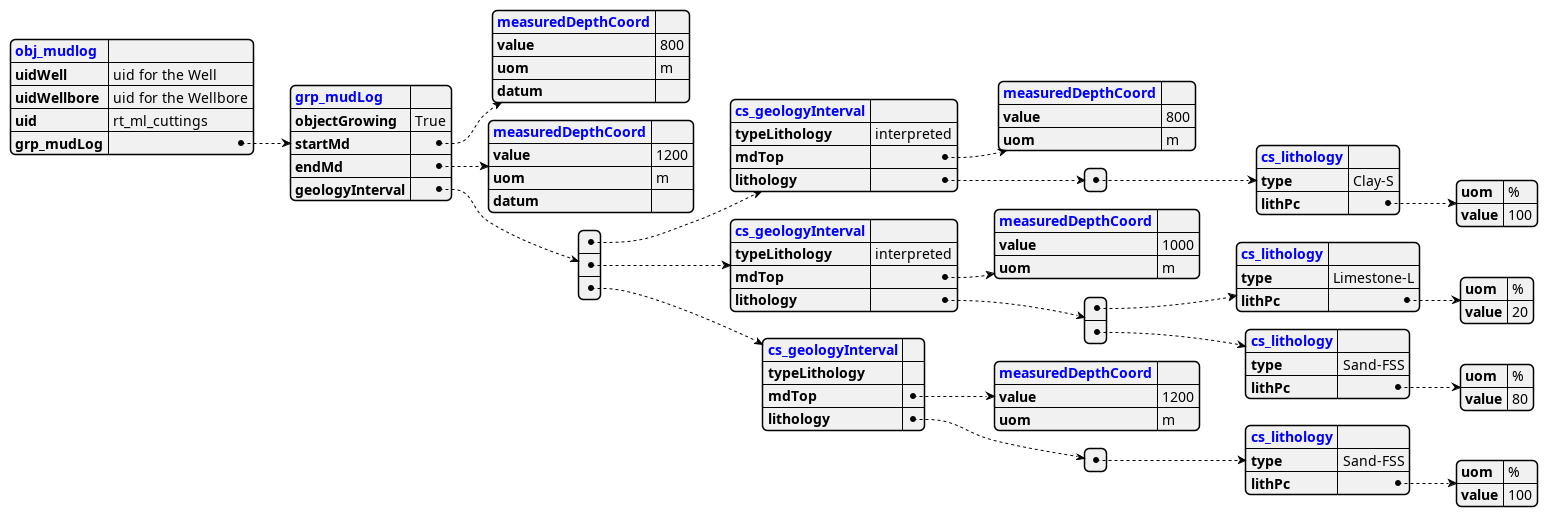
WITSML is defined by a set of XSD files with a very deep-nested structure. The extractor parses the XML structure to store it in CDF RAW, enabling flexible data navigation and consumption. If the linked types have an unbound relation, this qualifies for a new table in CDF RAW, where the table name has the new element added to the name. The parent key represents the link to the table above in the XSD hierarchy.
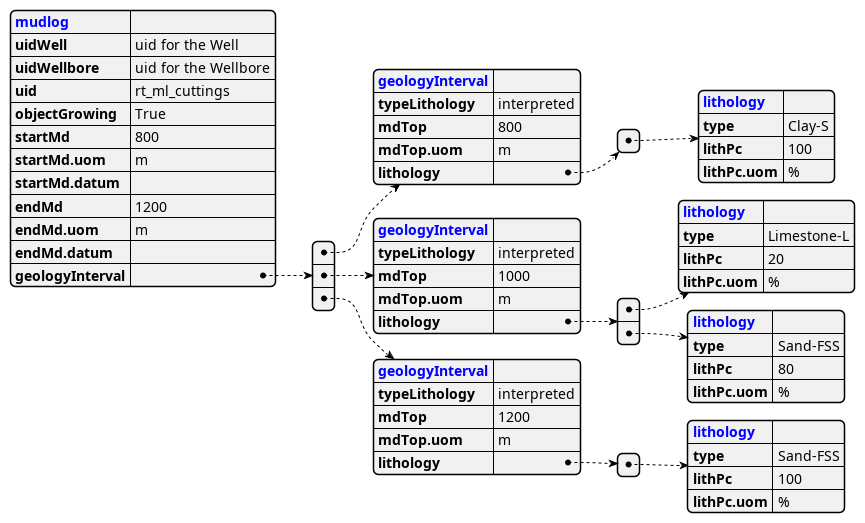
Example: WITSML MudLog structure
XSD structure:
All top-level types merged into one structure:
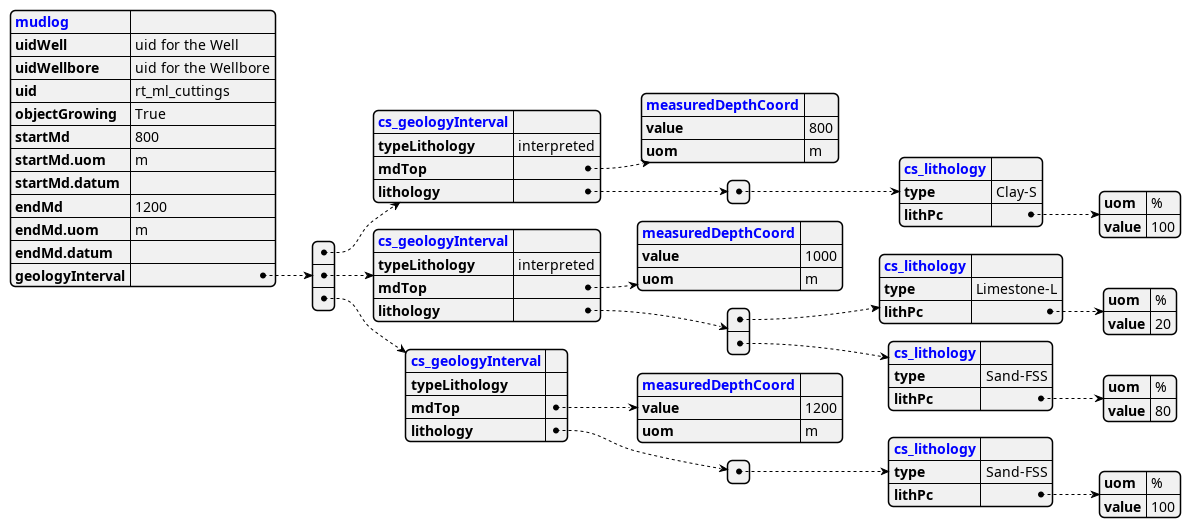
- All levels merged into distinct tables: